痛并快乐着
“碎片化”像一个魔咒,从android 平台问世那天至今,伴随其成长。客观的说,这样的多样性的确帮助android 俘获了数以亿计的用户,但却给该平台下的设计师和开发者带来了不小的挑战。学会适应这样的生态环境,不仅需要更加广泛的知识还需要更加高超的技巧。不过话说回来,在满足各式各样的用户的过程中,你将成为一个更好的设计师或开发者。不得不说,这是一个值得追求的挑战!
目标
想要收获挑战的胜利果实,必须要有一个明确的目标。本文并不想纠结于品牌、乃至OS 版本的碎片化等问题,那需要更多的篇幅和精力去探讨。这里只想专注于屏幕适配这一问题进行集中的讨论。
从OpenSignal这份报告来看,2014年支持android 的设备就有18796种,而设备屏幕的种类也是千奇百怪的。理想状态下,为每一种目标设备设计一套视觉资源,似乎就不存在适配的问题。但,没有一个设计师会愿意接受这种方案(工作量太大了好吗?)。就算有“勇士”接受了这样的设计任务,应用安装包也将变得臃肿不堪(apk太大了好吗?)。
这样看来,屏幕适配的目标就清晰了许多:尽可能设计可重用的视觉资源,让目标设备良好呈现。这通常需要视觉人员以及程序猿的通力配合,才能达到预期的效果,任何一方的懈怠,都会导致功亏一篑。
怎么搞
设计的好不好,决定了适配程度的优劣。这里谈到的设计与视觉效果关系不大,而主要是适配设计。从以往的经验来看,设计师们习惯了用视觉语言去描绘设计,而程序猿们则习惯了用代码去实现设计。所以适配问题只有在视觉走查这个阶段才会让双方感到蛋疼。
明确需要支持的范围
那么多屏幕,可能有很多并不是我们的目标用户(比如TV屏),将有限的精力瞄准该做的事从来不会有错。国内的一些第三方市场报告能够给我们这方面的“灵感”,另外Google 也会定时更新在全球范围内的统计报告(需要翻墙)。
使用模糊定位和相对布局
通常来讲,设计师们直接给出的标注往往会让android 程序猿们头疼。这是因为,设计稿通常绑定了一个静态的设备分辨率,这就导致其标注出来的数字具有相当的局限性——只对一种分辨率有效!。换句话讲,在适配屏幕的过程中,程序猿们并不希望看到一些硬编码的数值标注,因为这会使得这份设计过渡依赖当前这个分辨率,而使得适配难上加难了。
好在Android 平台为我们提供了强大的适配语言:使用wrap_content以及match_parent来描述单个控件的大小,还有超级强大的RelativeLayout来描述多个控件的组合……系统在运行时,会通过动态计算摆放它们的位置。用自然语言说,最好不要告诉程序员具体大小,而是告诉他们一些个相对数值。让我们看个例子:
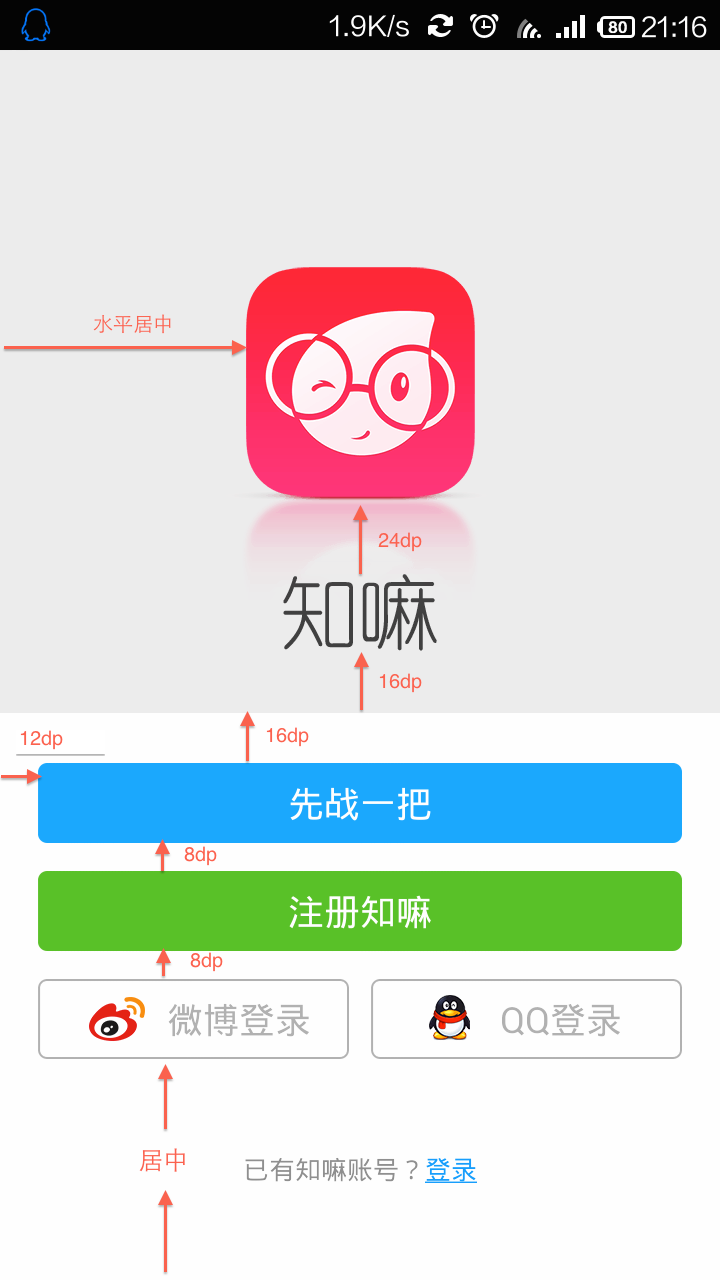
“先战一把”的按钮并不需要知道自身要有多长多宽(使用match_parent),而只要知道自己和周围的距离,就能摆放恰当了; 再看看应用图标的摆放甚至都不需要知道左右的相对距离(使用wrap_content),只要给出类似“水平居中”这样的模糊定位,即可良好呈现。
通常一个设计稿,如果从上到下,从左到右(反过来也行),能够让每个控件尽量使用模糊定位和相对布局,那么适配各种屏幕,简直就是轻而易举。不过,有些刁巧的设计并不适用于这类描述。那么这个时候,可能就需要产品经理去权衡展示效果和适配力度之间的问题了。
使用资源限定符
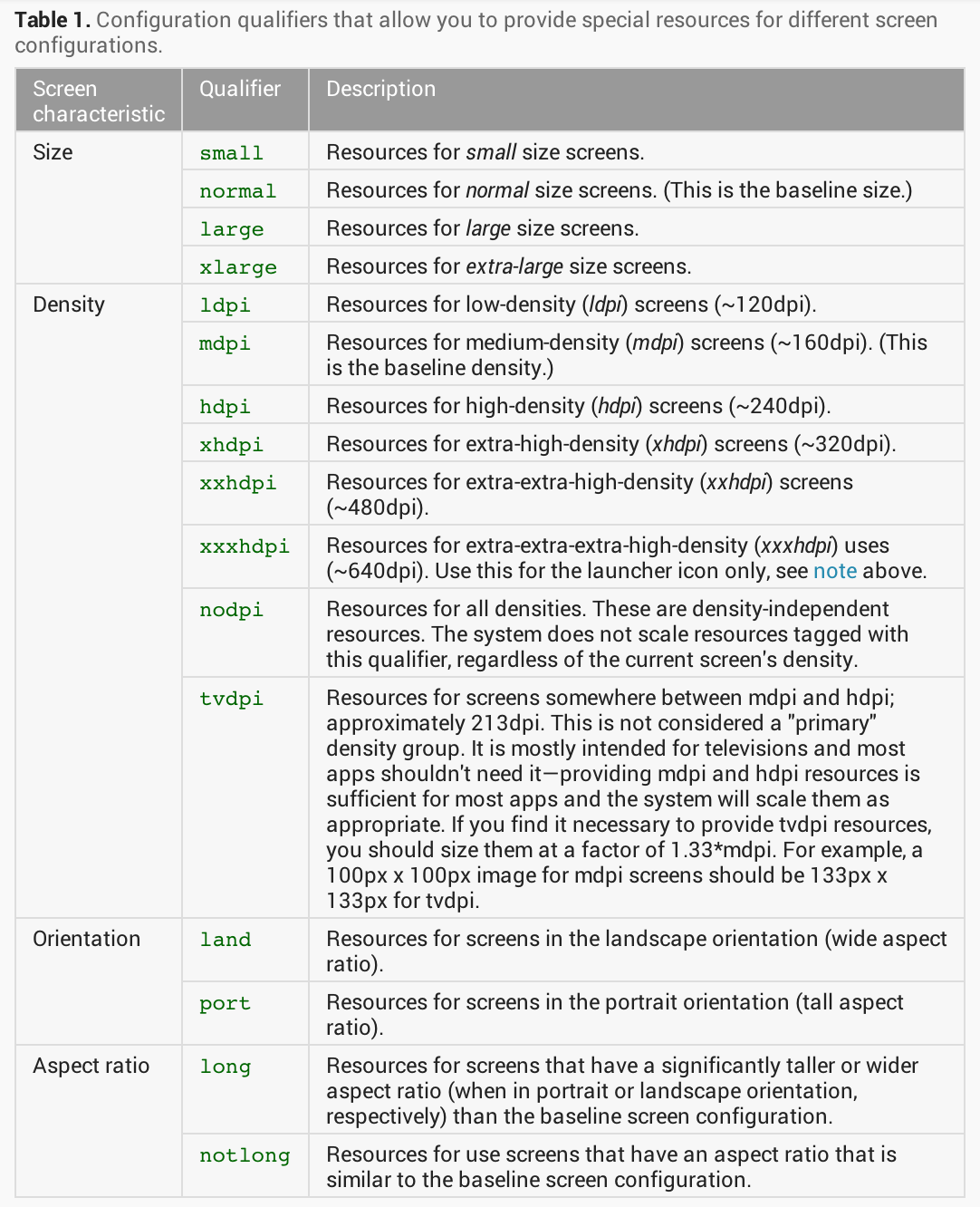
细心的读者可能已经发现,上面的方法虽然能够尽可能的规避具体控件的大小,但是“漏网之鱼”以及一些相对距离还是硬编码来的啊!虽然他们只是边边角角,但是为了视觉呈现的效果,还是可以使用资源限定符来进行适配的。简单的说,资源限定符可以让设备在程序运行的时候,自动选择与设备最匹配的资源。不过,在正式介绍资源限定符之前,恐怕还得介绍一些个相关概念:
- 屏幕密度:一言以蔽之,同样的物理尺寸,密度大的屏幕通常显示更为细腻。这是因为该屏幕单位面积内可以用来显示的“点”更多。所以,屏幕密度的单位是dpi(dot per inch,每英寸点)就很好理解了。这里还需要强调的是,屏幕尺寸和屏幕密度是2个独立的概念。一些个山寨手机虽然屏幕大,但显示效果却不尽如人意。这是因为山寨屏的单位面积内可用来显示的“点”太少,导致图像细节在显示过程中丢失。android 平台目前将屏幕密度分为6个等级:low(ldpi~120dpi), medium(mdpi~160dpi), high(hdpi~240dpi), extra-high(xhdpi~320dpi), extra-extra-high(xxhdpi~480dpi), and extra-extra-extra-high(xxxhdpi~640dpi)。
- 密度独立的像素(dp, Density-independent pixel): 是一个虚拟的度量单位,与屏幕密度无关。试想,在没有dp 的年代,直接使用像素去描述布局和位置。那么,1个像素在
ldpi的屏幕占1/120, 而在xxdpi的屏幕上只占1/480。那么同样的视觉设计在4寸山寨屏与4寸视网膜屏的显示会相差3倍!dp 的出现完美的解决了这个问题:系统会根据当前设备密度的需要,透明的缩放尺寸。
也许你已经看出,我们的适配都寄希望于系统的自动缩放了——嗯,我想你已经领悟到了精髓。现在继续来讲前面的“硬编码”问题。所以,即使是硬编码,我们也不能直接使用px来描述,而应该使用dp。那关屏幕密度什么事呢?关资源限定符什么事呢?
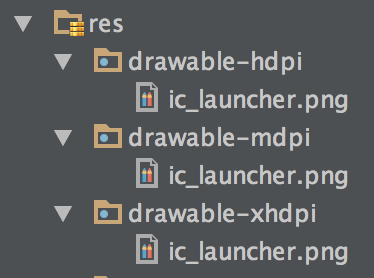
可以说,除代码外的所有静态资源,全部都分布在不同类型的工程目录下,而不同类型的目录还细分了各种属性,这些属性帮助系统在运行时能够根据设备自身的配置从相应的目录中动态的加载这些静态资源,以达到适配的效果。android 资源文件夹使用-来分割限定符。拿图片文件来说,drawable-hdpi文件夹所存放的图片适用于高密度(high density)的设备屏幕,而drawable-xhdpi则适用于超高密度(etra high density)的设备屏幕。下图所示的ic_launcher.png图片重复出现在了三个文件夹里。当请求名为 ic_launcher 的图片时,系统运行时会根据设备配置自动选择适应的图片。这能让我们根据不同屏幕尺寸最优化图片的显示,但是重复存储的图片势必造成浪费资源。
动态加载静态资源的过程,可能会遇到“找不到最合适资源”的情况。这个时候,系统会拿其他目录中同名的资源进行缩放处理。举个例子,系统需要加载drawable-xhdpi下的ic_launcher.png文件,但发现找不到!这个时候找遍了资源目录却发现只有drawable-hdpi下有ic_launcher.png。系统会毫不犹豫的加载,并将其放大1.3倍。设计师看到这里可能会有点激动,“放大?那图片资源会不会失真?”没错,这个担心很合理。所以,通常的做法是保证最高密度文件夹下有相应的文件,那么系统在动态加载的时候只会处理缩小的过程。
事实上,利用上面这个特点,我们在设计输出时,应该直接瞄准那些高密度规格的设备,比如1920 * 1080。一次输出后,填满drawable-xxhdpi文件夹。这样直接可以一次性适配的分辨率就有640 * 360、1280 * 720、960 * 540。
同理,前面谈到的硬编码的相对数值(静态常量资源),应该合理的分布在不同文件夹下的dimens.xml文件里。对,这里可能就需要视觉人员给出多套标注,以达到最大限度的复用!
你以为资源限定符就这样介绍清楚了?图样图森破!不过这段文字应该能够让你对动态加载静态资源有一个清晰的认识。想要了解更多,请访问developer.android.com 进行系统的学习。(*^__^*)
使用9-patch
那么多屏幕要适配,要是图片本身就有自适应的能力该多好啊!9 patch bitmap 将赋予你这种魔力。这是一种图片格式,允许设计人员定义图片能够被拉伸的区域,通常被用在背景性质的图片中。这样带来的好处是:一方面给背景显示带来了灵活性(可拉伸),另一方面还大大降低了图片的“重量”。官方提供了简便的制作工具(需翻墙), 网络上也有大量的文章介绍,这里就不再赘述了。显然,这类资源如果得到复用,那么必能极大地减小应用安装包的大小。另外,各种按钮、背景的图片资源如果能在设计时就考虑复用的话,那也必是极好的。
唠叨
android 平台提供的适配工具,我想先介绍到这里。本文没有提到“为特殊的屏幕类型提供不同的布局”这类细节,是因为觉得其工作原理和上述内容类似,当然太懒也是一个不容掩饰的原因。一句话总结,无非是提供可替换的静态资源,让系统自身去操心如何适配罢了。
参考文献
]]>